We present LODESTAR, a framework for learning robust long-horizon dexterous manipulation from a few human demonstrations. LODESTAR segments demonstrations into se- quential skills using off-the-shelf foundation models, and augments each skill via simulation-based residual reinforcement learning. The synthesized skill data is co-trained with real-world data, and a Skill Routing Transformer composes the learned skills into a robust autonomous policy capable of completing complex real-world tasks.
Developing robotic systems capable of robustly executing long-horizon manipulation tasks with human-level dexterity is challenging, as such tasks require both physical dexterity and seamless sequencing of manipulation skills while robustly handling environment variations. While imitation learning offers a promising approach, acquiring comprehensive datasets is resource-intensive. In this work, we propose a learning framework and system LODESTAR that automatically decomposes task demonstrations into semantically meaningful skills using off-the-shelf foundation models, and generates diverse synthetic demonstration datasets from a few human demos through reinforcement learning. These sim-augmented datasets enable robust skill training, with a Skill Routing Transformer policy effectively chaining the learned skills together to execute complex long-horizon manipulation tasks. Experimental evaluations on three challenging real-world long-horizon dexterous manipulation tasks demonstrate that our approach significantly improves task performance and robustness compared to previous baselines.
LODESTAR Pipeline. LODESTAR consists of three sequential stages. (1) Human demonstrations are segmented into manipulation and transition phases using discriminators built from VLM. (2) Each skill is augmented via residual RL in simulation to train robust policies. (3) Skill Routing Transformer policy composes and selects skills or transition actions during execution, enabling coherent long-horizon manipulation in real-world settings.




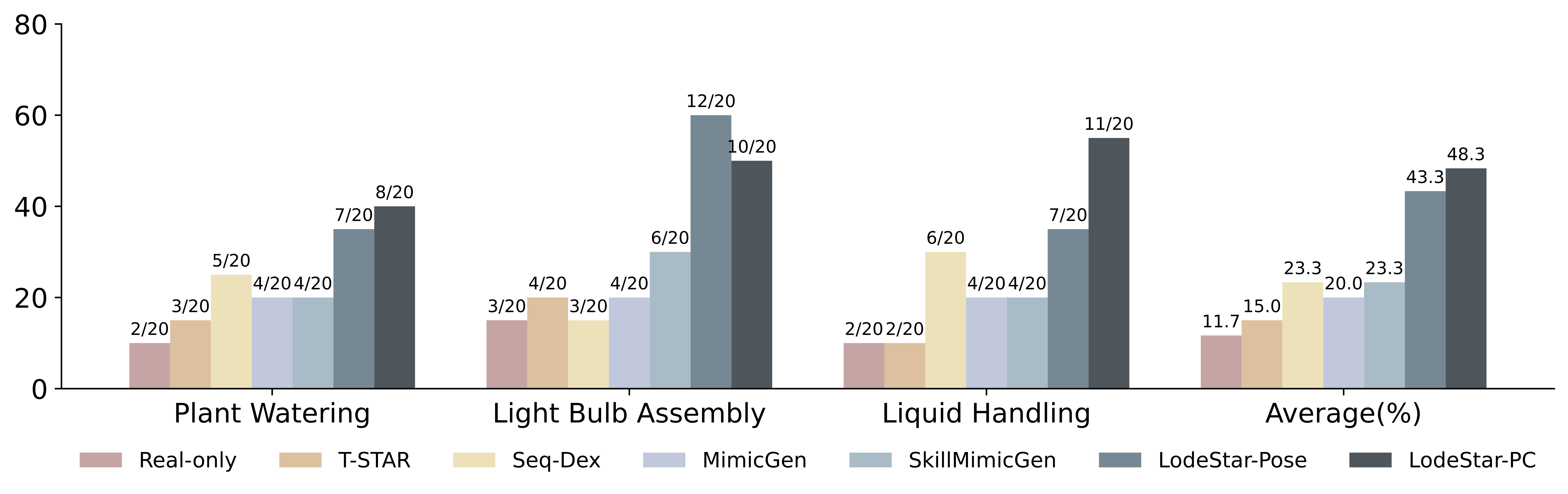
Success rates across three challenging real-world tasks and their average. LODESTAR-PC demonstrates superior performance on average and across tasks, boosting average success by at least 25% compared to the baselines.

Visualization of OOD experiments with a larger initial distribution condition. The red and blue rectangles represent the distribution of demonstration data for the initial pose of the light bulb and the black base. The multiple light bulbs and black bases illustrate different initial positions across evaluation episodes. Faded ones indicate failures, while solid ones indicate successes. Lodestar demonstrates stronger generalizability than the real-only baseline with fewer demonstrations.
Failure Cases Distribution on Three Tasks.